In the current cybersecurity landscape, determining if a system is truly vulnerable is a tedious, high-stakes game of manual correlation. Traditional vulnerability management relies on a fragile process: manually matching OS versions, hardware platforms, and—most critically—specific configuration states against security advisories.
While commercial scanning software can automate the retrieval of OS and hardware data, they often struggle with the nuanced “if/else” logic required for a high-fidelity assessment. For example, a CVE might only be exploitable if a particular feature, like MACsec or OSPFv3, is actively configured. Translating these human-readable conditions into code is time-consuming and prone to error, frequently resulting in a flood of false positives or, worse, missed detections.
I am excited to showcase a more intelligent approach: AI-Powered CVE Agents. By leveraging LLMs and agentic workflows, we can transform unstructured vendor advisories into a precision-guided assessment pipeline.
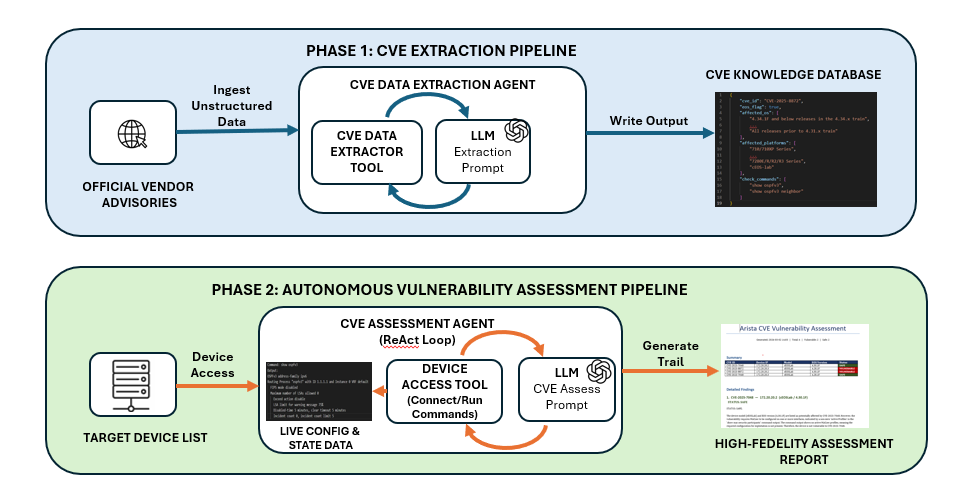
Phase 1: Intelligent Extraction
The first bottleneck in vulnerability management is the unstructured nature of security advisories. Our CVE Extraction Agent uses a specialized ReAct loop to crawl vendor portals (like Arista’s security advisory pages) and extract structured intelligence.
The Extraction Logic
The core of this phase is a “Role-Based” prompt that instructs the LLM to act as a precise data architect. It doesn’t just summarize; it identifies unique CVE IDs, maps affected OS releases, and isolates the “Required Configuration for Exploitation.”
Example Structured Data Output
The result is a clean, actionable record. Here is an example of what the agent extracted for CCVE-2025-8872 (an IPV6 OSPF related vulnerability). The details of Arista advisory can be found here https://www.arista.com/en/support/advisories-notices/security-advisory/23115-security-advisory-0128
{
"cve_id": "CVE-2025-8872",
"eos_flag": true,
"affected_os": [
"4.34.1F and below releases in the 4.34.x train",
...
"All releases prior to 4.31.x train"
],
"affected_platforms": [
"710/710XP Series",
...
"7280E/R/R2/R3 Series",
"cEOS-lab"
],
"check_commands": [
"show ospfv3",
"show ospfv3 neighbor"
]
}
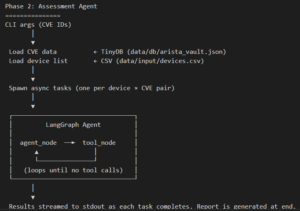
Phase 2: Autonomous Assessment
Once the database is ready, a second agent—the Assessment Agent—takes over. Unlike static scanners, this agent follows an autonomous loop: it retrieves the necessary diagnostic commands, connects to the devices, and feeds the live output back into the LLM for a final verdict.
The Assessment Prompt
To ensure accuracy, the agent is governed by a strict prompt that forbids guessing. If a device’s OS and model match a CVE, the agent must call the run_check_commands tool to verify the active configuration before issuing a status.
- Instruction: “If the device model and OS match a CVE, you MUST call this tool [run_check_commands] before answering.”
- Verification: “Analyze the tool output… Final Answer should start with ‘STATUS: VULNERABLE’ or ‘STATUS: SAFE’ followed by reasoning.”
Phase 3: High-Fidelity Reporting
The culmination of this pipeline is a detailed, automated assessment report. Instead of a simple “vulnerable” flag, the AI provides a reasoned explanation for every device in the fleet, significantly reducing the “noise” for security teams.
Sample Assessment Report
Below is a snippet of a generated report showing how the agent differentiates between a potentially affected OS and an actually vulnerable configuration.

Conclusion
By shifting from static, rule-based scanning to AI-driven agentic workflows, we can finally achieve the scale and precision required for modern infrastructure. This approach doesn’t just find vulnerabilities—it understands them in the context of your unique environment.
This project is built using Python, LangGraph, and Scrapli. In the next post, I will walk through the code implementation in details.