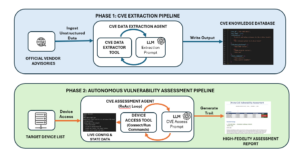
In Part 1, we explored why traditional vulnerability scanning often falls short due to high false-positive rates and manual correlation. Today, we move into the Software/AI Defined implementation, breaking down the Python architecture that enables our autonomous intelligence pipeline.
1. Phase 1: Building the Extraction Pipeline
The goal of Phase 1 is to turn unstructured vendor advisories into a machine-readable database.
Intelligence Scraping with crawl4ai
The foundation of a context-aware assessment is high-fidelity data. We use crawl4ai to navigate the Arista Security Advisory portal. The tool handles the complexities of modern web rendering and delivers a clean Markdown version of the advisory to our extraction agent.
Structured Extraction with Pydantic
To ensure the LLM outputs are reliable, we define a strict model that acts as a blueprint for the extracted data.
Python
class Vulnerability(BaseModel):
cve: str = Field(description="CVE identifier, e.g. CVE-2024-1234")
affected_os: List[str] = Field(description="Affected EOS versions")
affected_platforms: List[str] = Field(description="Products explicitly marked 'are affected'")
commands: List[str] = Field(alias="commands", description="Arista EOS CLI commands that verify the vulnerability")
eos_flag: bool = Field(alias="EOS_flag", description="True when the affected product is EOS")By leveraging with_structured_output, we force the LLM to adhere to this schema, ensuring that our TinyDB database contains only valid, actionable records.
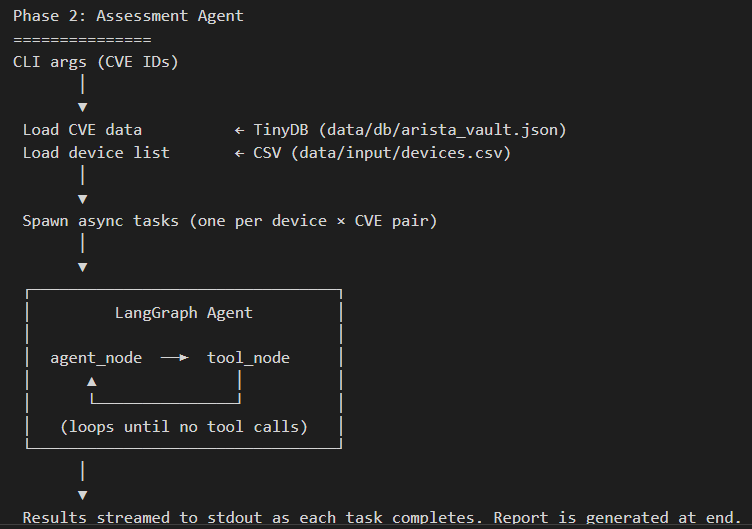
2. Phase 2: The Autonomous Assessment Loop
With a structured intelligence base, we can deploy our Assessment Agent to verify vulnerabilities on live devices using a ReAct (Reason + Act) pattern.
State Management with LangGraph
We use LangGraph to manage the agent’s decision-making loop. The agent observes the device OS and hardware platform, reasons about the CVE requirements, and acts by calling diagnostic tools.
- The Agent Node: The LLM determines if a device is potentially vulnerable based on its OS and model.
- The Tool Node: If a match is found, the agent autonomously executes the pre-defined check commands on live device via tool.
- The Verification Loop: The output of these commands is fed back to the agent, allowing it to “see” the configurations or states and make a final determination.
Device Interaction via Scrapli
The agent uses Scrapli to perform asynchronous SSH connections to Arista switches. This allows the agent to execute commands like show ospfv3 in real-time and capture the results for analysis.
3. Operationalizing the Workflow
Handling Scale with Semaphores
Assessing an entire network requires scale. We implement asyncio.Semaphore to manage concurrency, allowing hundreds of simultaneous checks without overwhelming network devices or exceeding LLM rate limits.
High-Fidelity Automated Reporting
The final output is a professional Word report that provides an executive summary and detailed AI-driven reasoning for every finding.
- Summary Table: Provides an executive view of the “Vulnerable” vs. “Safe” status across the fleet.
- Detailed Findings: Each entry includes the AI’s reasoning, explaining exactly why a device was marked Safe (e.g., “The vulnerable feature is not configured”) or Vulnerable.
Summary
This implementation demonstrates that the future of CVE assessment is Software/AI Defined. By combining Pydantic, LangGraph, and Scrapli with LLM, we have replaced manual “guesswork” with autonomous, context-aware verification.
GitRepo: https://github.com/QTechsolutions-net/ai-powered-cve_agents.
Note: In my Gitrepo code, I use direct tool calls to better illustrate the agentic behavior of the LLM. If your tools are exposed via MCP, that can serve as an alternative.